Дампы Ru.Wikipedia.Org (ИП-0)
В статье рассматривается задача обработки и подготовки дампов русской википедии (http://ru.wikipedia.org/) к использованию в полнотекстовом поиске, и прочее всякое, что можно сделать с крупными дампами.
Полнотекстовый поиск - автоматизированный поиск документов, при котором поиск ведётся не по именам документов, а по их содержимому, всему или существенной части.Сканирование всего содержимого документов в поиске заданного слова и фразы может занимать очень большое количество времени, особенно если пространством поиска является википедия (я не говорю уже про весь интернет, где такой способ вовсе неприменим). Следовательно на основе текстовых данных, по которым будет вестись поиск, необходимо строить индекс, по которому организовывать быстрый поиск. В случае википедии текстовые данные могут быть легко получены из дампов.
Пока речь пойдет о том, где дампы доставать и как их готовить, - маленькая разминочная статья перед будущим циклом, в котором будут рассмотрены основы информационного поиска. На написание вдохновлен курсом “Информационного Поиска” Андрея Калинина, хотя все конечно будет рассмотрено не так подробно, но надеюсь, что выйдет хоть и компактно, но полезно и информативно.
Добыча дампов
С добычей дампов проблем никаких нет, потому что Вики сама делится своими самыми свежими дампами.
Дампы доступны по ссылке https://dumps.wikimedia.org/ и предлагаются в различных форматах, но стоит заметить, что самые свежие это всегда Database backup dumps, обновляются чуть ли не каждую неделю. Но если, скажем, вам не принципиальна новизна и нужны html-представления документов, то можно глянуть в Static HTML dumps. Но мой личный совет - это чуть больше запариться, скачать дампы, а потом вытащить от туда и оформить документы в нужный формат.
Если выбран последний вариант, то переходим на страничку бэкапов, жмем Ctrl + F и ищем “ruwiki”. Переходим. Теперь нужно найти файл формата ruwiki-<дата дампа>-pages-articles.xml.bz2 , если в описании к файлу есть что-то про articles, templates и mediafile descriptors и весит он около 3GB, то скорее всего это то, что нужно. Вне архива дамп весит около 18 гигабайт, и лучше иметь на харде побольше свободного места. Сейчас это уже не кажется большим размером, но у меня реально возникла проблема с местом на виртуалке.
Для получения из дампов непосредственно страничек википедии в html (да и не только) представлении можно воспользоваться утилитой WikiExtractor.
python3 WikiExtractor.py -o <output_folder> --html <dump_xml_file>
Подсчет слов
Из полученных удобно-читаемых файликов можно собрать какую-нибудь статистику по документам. Вот небольшой скрипт на питоне, который соберет некоторые характеристики документов в csv-подобный формат. Скрипт обходит все файлы, сгенерированные wikiextractor’ом и производит подсчет слов, символов, заголовков, ссылок на другие страницы.
import os,re,sys
output = open('stats.csv','w')
summary = open('summary.txt','w')
summaryWords = 0
summarySymbols = 0
summaryDocs = 0
#regex for detect tags in html wiki docs
htmlTagsRegex = re.compile(r"(<.*?>|<.*?>|[\.,()—;:\[\]\{\}\*\%\"\'!?])")
linksRegex = re.compile(r'<a href.*?>(.*?)<\/a>')
spaceRegex = re.compile(r"[\s\n]")
for directory in os.listdir("out"):
dirpath = os.path.join("out",directory)
if os.path.isdir(dirpath) == True:
for filename in os.listdir(dirpath):
file = open(os.path.join(dirpath,filename))
# [id, title, words, symbols, h2, h3, h4, links, filename]
article = []
wordcount = 0
symbolcount = 0
h2count = 0
h3count = 0
h4count = 0
linkscount = 0
for line in file.readlines():
m = re.match(r'<doc id="(.*)" url="(.*)" title="(.*)">', line)
if m:
article.append(m.group(1)) #id
article.append(m.group(3)) #title
elif line.startswith("</doc>"):
summaryDocs += 1
summaryWords += wordcount
article.append(wordcount)
summarySymbols += symbolcount
article.append(symbolcount)
article.append(h2count)
article.append(h3count)
article.append(h4count)
article.append(linkscount)
article.append(os.path.join(dirpath,filename))
output.write("|;|".join(map(str,article)) + "\n")
article = []
wordcount = 0
symbolcount = 0
h2count = 0
h3count = 0
h4count = 0
linkscount = 0
else:
if line.startswith("<h2>"):
h2count += 1
if line.startswith("<h3>"):
h3count += 1
if line.startswith("<h4>"):
h4count += 1
linkscount += len(linksRegex.findall(line))
rawLine = htmlTagsRegex.sub('',line)
wordcount += len(rawLine.split())
rawLine = spaceRegex.sub('',rawLine)
symbolcount += len(rawLine)
print('{} folder complete'.format(directory))
summary.write('Docs: {}\nWords: {}\nSymbols: {}\n'.format(summaryDocs, summaryWords, summarySymbols))
output.close()
summary.close()
На выходе получится файл с записями такого формата: >Id статьи|;|Заголовок статьи|;|Количество слов в статье|;|Количество символов в статье|;|Количество заголовков h2 в статье|;|Количество заголовков h3 в статье|;|Количество заголовков h4 в статье|;|Количество ссылок в статье|;|Путь к файлу исчтонику
Результат, открытый в программе Gnumeric, выглядит следующим образом:
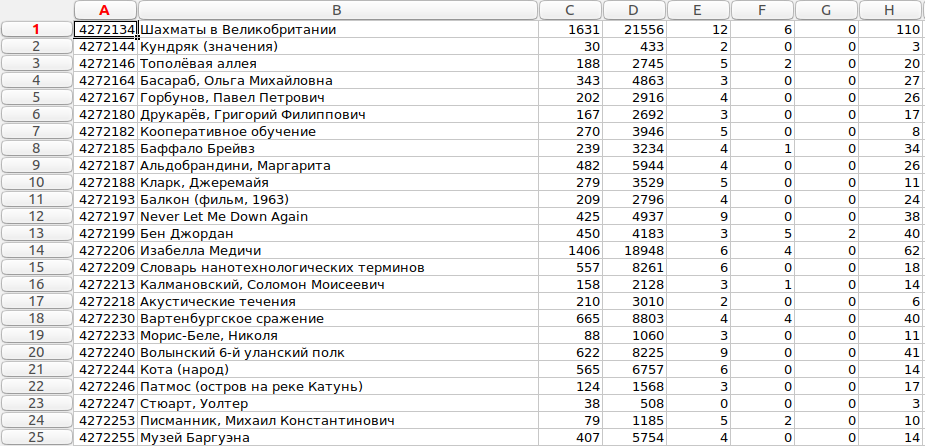
На тот момент, когда я скачивал дамп, в русской википедии было 1370124 статьи. А самой объемной статьей - Список персонажей Fairy Tail (575455 символов), что для меня было некоторым сюрпризом. Следом по объему, к слову, идет серия статей про немецкие эскадры истребителей времен второй мировой Jagdgeschwader.
Распределение
Можно еще из полученного файла со статистикой посчитать распределение статей по их размеру и построить гистограмму.
import numpy as np
import matplotlib.mlab as mlab
import matplotlib.pyplot as plt
stats = []
iter = 0
with open('stats.csv', 'r') as csvfile:
for record in csvfile.readlines():
stats.append(record.split("|;|"))
iter += 1
if(iter % 100000 == 0):
print(iter)
#0 - 10000
fig, ax = plt.subplots()
# the histogram of the data
n, bins, patches = ax.hist(map(lambda x: int(x[3]),stats), map(lambda x: x*100,np.arange(101)))
ax.set_xlabel('Symbols in article (step 100)')
ax.set_ylabel('Number of articles')
plt.title('Histogram 0-10000 symbols')
fig.tight_layout()
plt.savefig('hist.png')
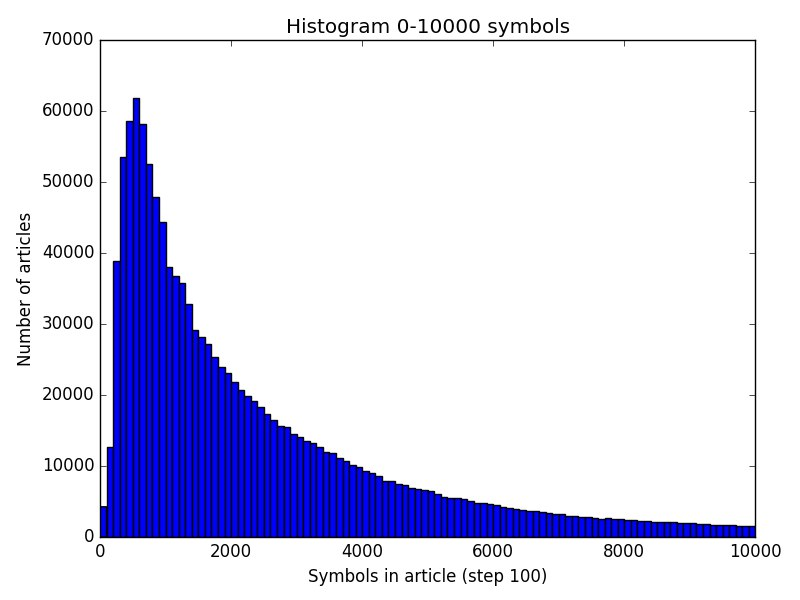
Самое большое скопление статей приходится на диапазон 300-1000 символов. Статей меньшего размера резко меньше - вероятно они не информативны, и они либо разрастаются, либо удаляются, либо представляют из себя различного рода перенаправления.
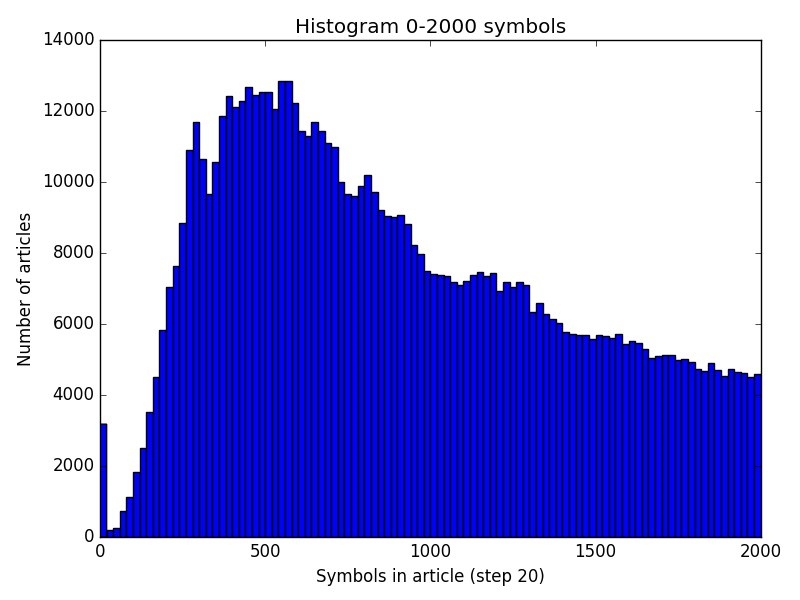
Можно немного увеличить масштаб. Тенденция плавного уменьшения количества статей при росте их размера вполне ожидаема. График становится похож на логарфмически-нормальное распределение.